I’m just finishing a project in the Centre for Digital Music (C4DM) that involved creating a couple of new Vamp plugins from machine-learning models for music audio.
- MERT Vamp Plugin: a feature extractor for MERT audio features
- Vamp Lossy Encoding Detector: detect whether music audio has previously been encoded via lossy compression
A Vamp plugin is a native-code module that can be loaded and run in various visualisation or batch-analysis tools to produce some potentially useful structured output based on an audio input.
(There was a time when a large part of my job at C4DM was packaging research work into Vamp plugins, or helping others do so — you can see some discussion in this old series of blog posts about entering them into the MIREX evaluation exercise, or in other posts about pYIN, Chordino, et cetera. Those efforts pre-dated the general switch from feature-engineering to neural-network learned features, so it’s been interesting to go back and look again in a new light.)
MERT Vamp Plugin
MERT is a machine-learning model that converts music audio into sequences of feature vectors that can serve as input for various “music understanding” tasks. These features are not expected to be directly interpretable on their own, but to capture patterns that can be used in training further models for specific activities (transfer learning).
This MERT Vamp plugin can be used by a Vamp host application to convert music audio into these features. It provides separate outputs for features extracted from the 12 hidden layers of the MERT-v1-95M model, potentially useful for different sorts of music interpretation task.
We can see the “not directly interpretable” part at work by running the plugin in Sonic Visualiser. Here’s an example, with a time-frequency spectrogram at top and one of the MERT layer features below.
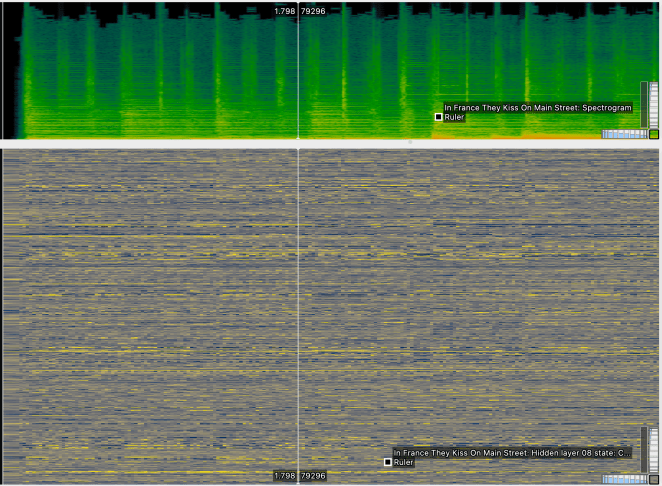
We have 50 features per second with 768 bins per feature, and although there is clearly some correspondence in time between events visible in the spectrogram above and changes in the MERT features shown below, it’s not obvious to the eye what that correspondence is. But the idea is that a model subsequently trained with these features as input, relatively cheaply against a labelled set of examples, may perform better at certain higher-level music classification tasks than would be practical to achieve with similar resources directly.
Lossy Encoding Detector
The output of the other plugin is even more underwhelming to inspect with Sonic Visualiser:

This plugin analyses an audio file to figure out whether it has at some point passed through a lossy music audio compression algorithm such as mp3. Of course it looks only at the audio signal to do this, not the file extension! So if you decompress an mp3 into a wav file and analyse that, it should still identify it as lossy.
The publication history of this kind of method is a neat microcosm of the wider audio analysis space. There are some pretty sophisticated-looking methods published in the years up to the mid-2010s, generally working through some statistical comparison against the properties of specific lossy encoders. Then in 2017 we see the paper Codec-independent lossy audio compression detection which just converts the audio to spectrograms, trains a simple convolutional image classifier using a pile of lossless and lossy examples, and achieves a 99% detection rate.
This plugin is basically that method, but with an even simpler model, retrained using some CDs I happened to have. In fact, the model is much the same as the one I wrote about in What does a convolutional neural net actually do when you run it? which makes it about as simple as it could reasonably be.
And a new release of Sonic Annotator
While I’m writing about plugins that are most useful in batch mode: I also just wrapped up a new release of Sonic Annotator (v1.7). There is really very little new here; the main purpose is to update the code to the Qt6 libraries to match the respective non-GUI parts of Sonic Visualiser.
