Today marks version 3.1 of the audio time-stretching and pitch-shifting library Rubber Band. This release focuses primarily on performance improvements.
In version 3.0 we introduced a totally new, higher-quality processing engine, which I’ll refer to as the R3 engine. The older one is still included, and I’ll call that R2.
Although the output of R3 typically sounds much better than R2, it uses a lot more CPU power to run. Measuring sustained throughput in frames-per-second for common fixed stretch factors, we find R2 to be typically about three times as fast as R3. Both are eminently usable in real-time on hardware from the last decade, but the headroom available for R2 can make a big difference.
It would be nice to do better, but the R3 code was already quite heavily optimised before release — it is simply a fairly CPU-intensive method. Still, as it turns out, there are a few things we can do.
Measuring performance
Sustained throughput is not the only measure. Rubber Band is often used in real-time situations where the worst-case time per processed block is what matters most.
To measure this, I set up a test case that simulates a typical sound processing callback, passing a music recording through a stretcher and emitting a fixed 512 sample frames from each processing cycle, while varying the time and pitch ratios and measuring how long each cycle takes to return. The stretcher is initialised with typical parameters for this activity (in code terms, OptionProcessRealTime | OptionPitchHighConsistency | OptionFormantPreserved) and it is primed with an initial pad before entering the cycle loop, as otherwise the first call would dominate results.
The results for R2 and R3, as of the 3.0 release, look like this: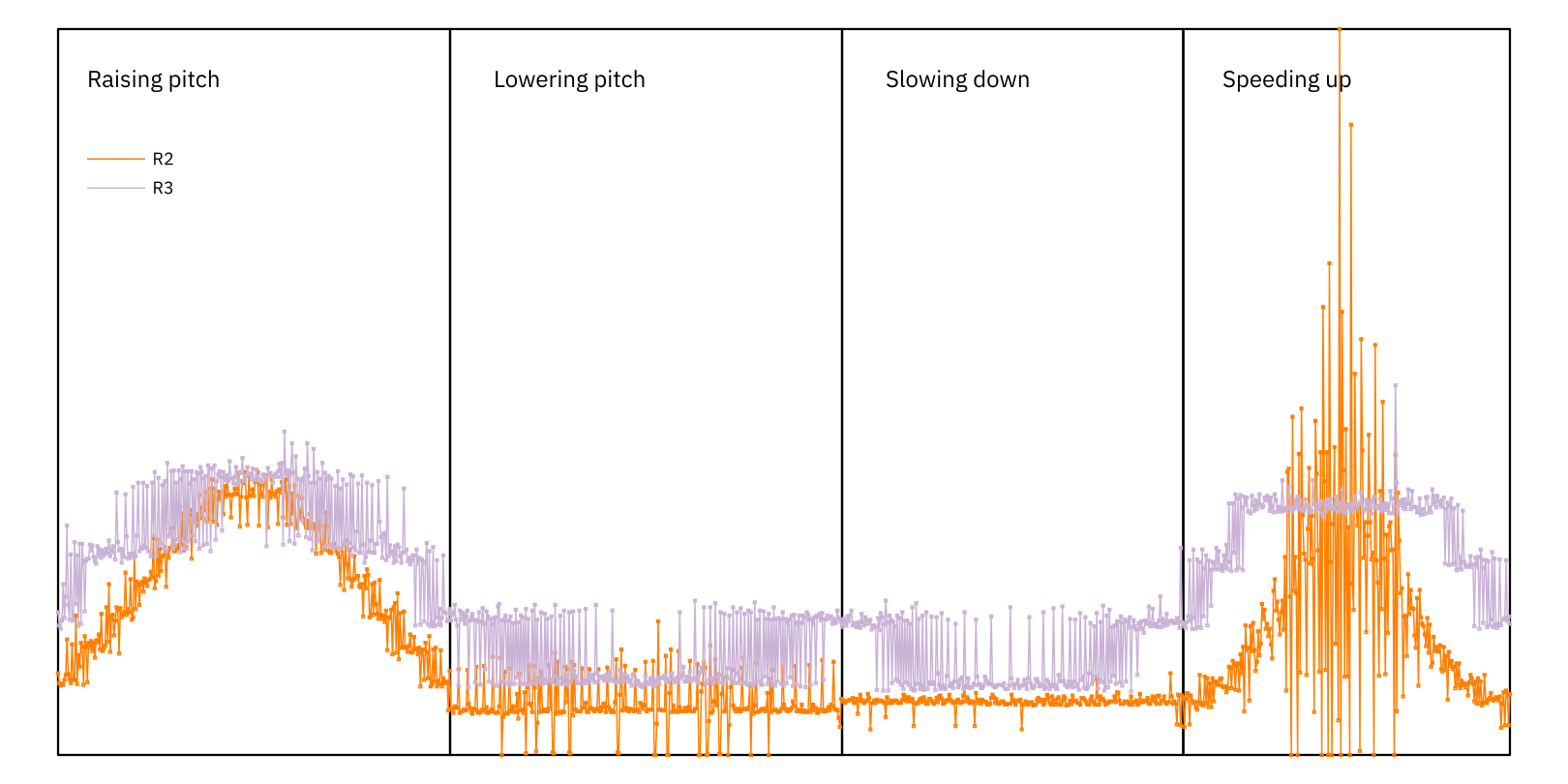 This is a graph of processing cycle count (x-axis) against time taken per 512-frame cycle (y-axis). The y-axis is linear in time with zero at the bottom, so lower is better. No units are shown because they are totally system-dependent — this is purely a comparative visualisation, we’re only interested in the relative heights. Obviously the relative heights may also vary from system to system, so this is still quite tentative.
This is a graph of processing cycle count (x-axis) against time taken per 512-frame cycle (y-axis). The y-axis is linear in time with zero at the bottom, so lower is better. No units are shown because they are totally system-dependent — this is purely a comparative visualisation, we’re only interested in the relative heights. Obviously the relative heights may also vary from system to system, so this is still quite tentative.
The test runs in four consecutive phases with different pitch and time modifications, and so the x-axis is divided into four (uneven) quadrants: raising pitch, lowering pitch, slowing down, and speeding up.
In the first quadrant, the pitch rises smoothly and then falls again, reaching a peak at two octaves up; in the second it falls smoothly and then rises again, reaching a trough at two octaves down; in the third the pitch is unchanged but the tempo slows to just under a third of the original speed and then returns to normal; and in the fourth quadrant the tempo gradually speeds up to 8x the original speed and then returns to normal.
The plots for R2 (orange) and R3 (purple) reveal significant differences in behaviour:
- R2 is usually faster, sometimes much faster, especially for modest stretch factors.
- R3’s long internal processing buffers and step size mean that it hops between “modes” depending on how many processing increments (1, 2, 3, 4 or occasionally 0) are required for each output block.
- R2 has less widely-spaced distinct “modes”, because it uses smaller increments. It’s still faster because it does so much less work for each increment.
- R2’s processing time becomes very variable, and relatively high, when speeding up the audio by a large factor (above about 3x). This may be because it continues to perform transient detection and adjust its input and output steps accordingly, and at those rates our test file contains a lot of transients. R3 is very predictable in this area by comparison.
- Both stretchers use increasingly more CPU when pitch-shifting further upward, but not when shifting down.
The last point happens because we are using OptionPitchHighConsistency. This option ensures that the resampler used for the pitch-shift part of the operation is always engaged, so that there are no discontinuities when changing ratio (particularly to or from the 1x ratio). We’ll come back that later.
A Draft Mode for Finer Mode
The main novelty in version 3.1 is an option to deactivate R3’s multi-window processing system, dropping down to a single shorter processing window and potentially running much faster, while retaining its more advanced signal analysis and some of its output characteristics.
This is enabled using the OptionWindowShort flag when constructing a stretcher, or the --window-short argument to the command-line tool. It’s an option that already existed in R2, and conceptually it does something similar there, but the effect on performance is much greater with R3.
Here’s a plot comparing R2, R3, and the new R3 single window option (“R3short”):
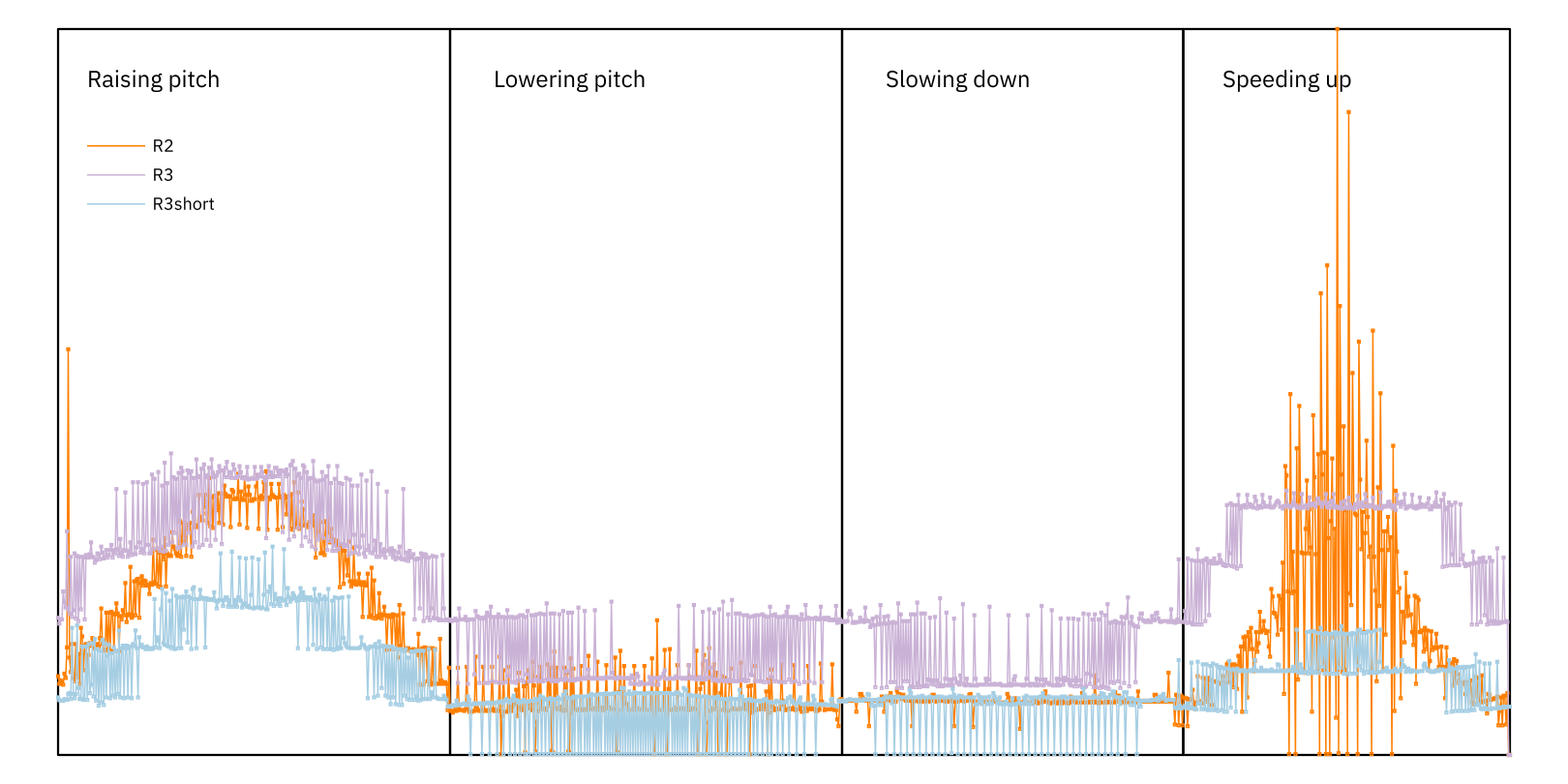 With this new option we get both performance comparable to R2 and the more predictable behaviour at high tempo ratios found in R3. Splendid.
With this new option we get both performance comparable to R2 and the more predictable behaviour at high tempo ratios found in R3. Splendid.
What does it sound like? Not as good as R3; it loses some percussive clarity and quite a lot of low-end stability. For some material, particularly acoustic instruments and vocals without too much bass content, it can sounds markedly better than R2. It’s not a universal substitute, but it’s really not bad given the CPU budget.
Here are some ten-second audio clips to give you an idea. Both are stretched to 140% of their original duration using R2, R3 with short window, and full R3. Neither of these is trivial to handle, though the second is far harder than the first.
- Haydn: Piano Trio no 43 in C major (Beaux Arts): original; R2; R3-short; R3
- 50FOOTWAVE: Somebody To Love (cover of Jefferson Airplane song): original; R2; R3-short; R3 (this recording is CC-BY-NC-SA)
Resamplers and FFTs
Rubber Band makes heavy use of audio resampler and fast Fourier transform (FFT) implementations. Originally it used external libraries for both, but in June 2021 a built-in FFT was added and in October 2021 a built-in resampler appeared as well.
These are both slower than the best external libraries, but they make Rubber Band simpler to build and integrate. And the built-in resampler is also designed to reduce clicky artifacts and maintain tempo integrity on ratio changes, at some further expense in performance, so if you do have the headroom it is worth defaulting to.
Here’s a performance comparison of the built-in resampler with libsamplerate in the “draft” short-window R3 mode described above.
 Clearly libsamplerate is both faster and more predictable. It’s faster even when changing only the tempo, which doesn’t involve resampling, because of our previously-mentioned use of
Clearly libsamplerate is both faster and more predictable. It’s faster even when changing only the tempo, which doesn’t involve resampling, because of our previously-mentioned use of OptionPitchHighConsistency which keeps the resampler running at all ratios.
(Incidentally all of the other performance plots in this post were made using libsamplerate, unless otherwise specified. Its smoother performance profile makes other comparisons easier.)
I’ve mentioned OptionPitchHighConsistency a couple of times now. If we use OptionPitchHighSpeed instead, we get quite different behaviour:
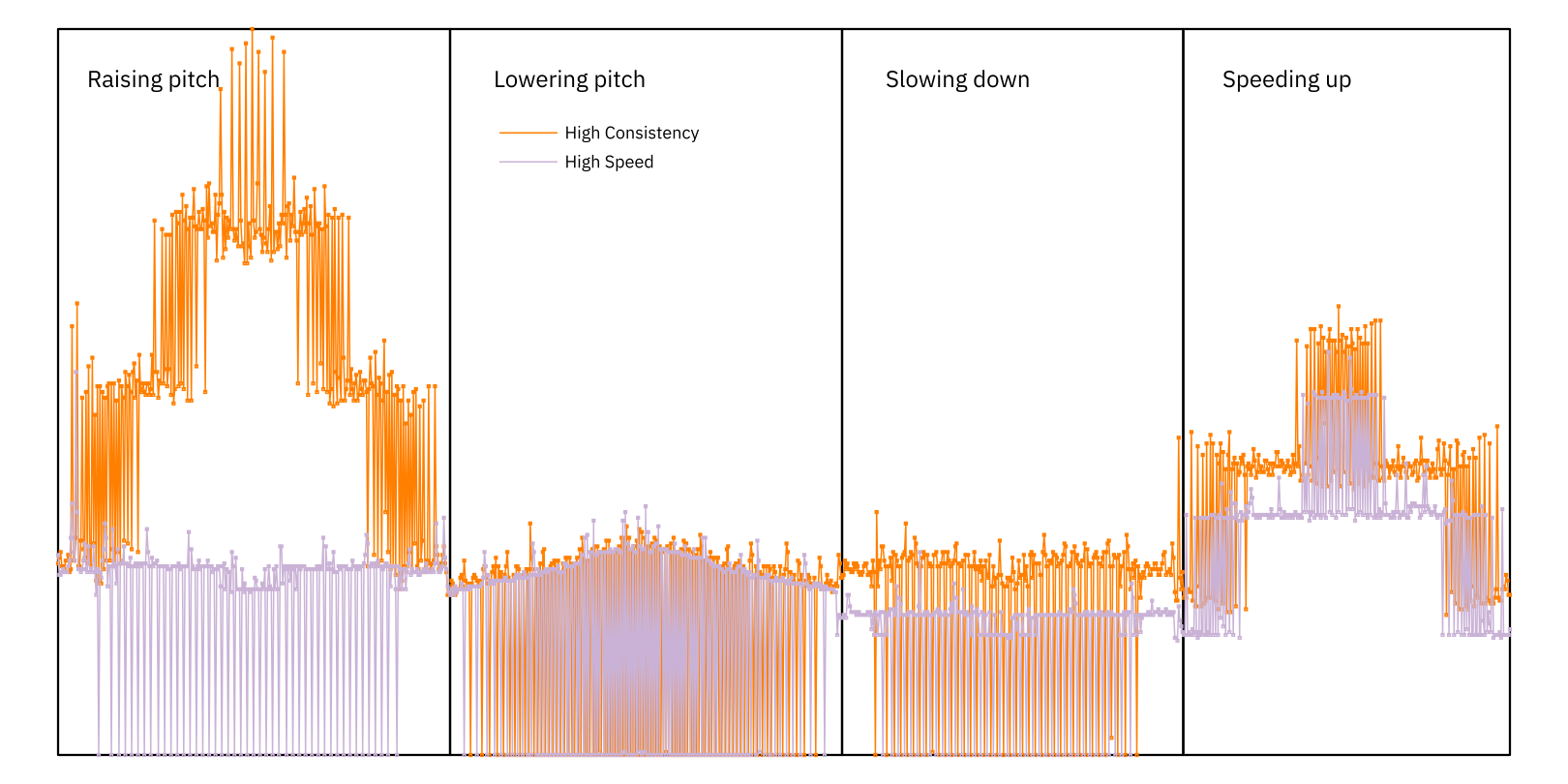 The relation between the amount of pitch shift and the CPU effort is totally gone. All pitch shifts are roughly equal, and the time-stretching quadrants are faster. The tradeoff, unfortunately, is that there are now audible discontinuities every time the pitch ratio reaches or crosses 1.0.
The relation between the amount of pitch shift and the CPU effort is totally gone. All pitch shifts are roughly equal, and the time-stretching quadrants are faster. The tradeoff, unfortunately, is that there are now audible discontinuities every time the pitch ratio reaches or crosses 1.0.
Traditionally the alternative to libsamplerate in Rubber Band has been a resampler implementation cribbed from the Speex audio codec and provided with Rubber Band as a compile-time option. This resampler was a bit unsatisfactory for various reasons, but a much improved version of it has for a while been available in a library called speexdsp.
As of v3.1 Rubber Band now includes support for speexdsp as well, and it works well — audio quality seems good, and so is performance on my test hardware, shown here against libsamplerate:
 I don’t think this is well-exercised enough to be a standard recommendation yet, but it’s promising.
I don’t think this is well-exercised enough to be a standard recommendation yet, but it’s promising.
The built-in FFT fares better than the resampler, but in addition to the previously-supported external libraries (FFTW, IPP, and Apple’s vDSP) this release also adds support for FFTs from SLEEF, a library which looks as if it should be competitive on platforms that have been short on good options in the past.
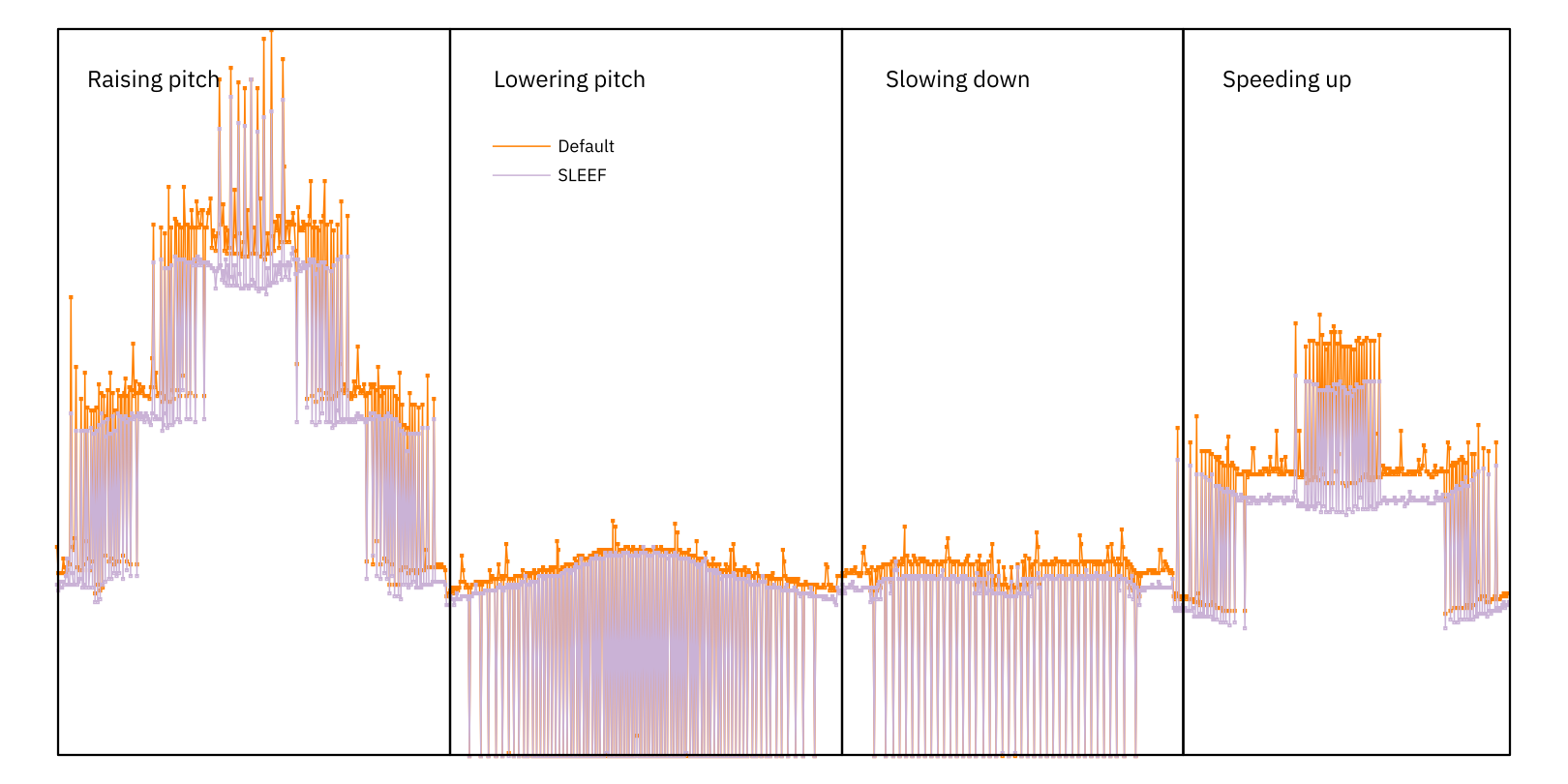
To summarise:
- The R3 time-stretcher and pitch-shifter engine introduced in Rubber Band 3.0 sounds great, but is relatively CPU-intensive compared to the older R2
- The new 3.1 release introduces a draft mode (“short-window” or single window mode) for the R3 engine, that retains some of its good qualities while running much faster and with more predictable CPU usage
- You may be able to speed up your implementation by using an external resampler or FFT library, and the 3.1 release adds support for a couple of new ones with good performance.
See the Rubber Band Library site for more information about the library.
Thank you for your time. Perhaps we can help you make more of it.
* * *
Many thanks to Davy Wentzler for valuable feedback on the 3.1 development process.
